












Understanding Neural Networks







If you’ve read some of my previous articles such as Using ChatGPT to Analyze Your Test Data, Using Generative AI to Write and Run Embedded Code, and Having a Conversation With Your Design Using AI Digital Twins, you may have noticed that I’m wild about AI and what it can do for engineers. From generating code to analyzing our designs, AI helps us be more productive in our daily lives. In this article I want to take a step back and provide a “light” understanding on what Neural Networks, the backbone of modern artificial intelligence, are and how it provides us with a new set of tools that we were never able to take advantage of in the past. We will also look at an example of how to build a Neural Network using a modern machine learning framework called PyTorch to create our own AI program.
The What and Why of Neural Networks
Rather than diving into what neural networks are, it's important to understand why we need them and what they provide for us as an alternative to normal, rule-based programming. Neural networks consist of interconnected nodes, or neurons, organized in layers. These networks can learn complex patterns from data, making them powerful tools for tasks such as image recognition. In this article, we’re going to create an example AI program capable of recognizing handwritten numbers. After training our model, we should be able to give it a handwritten number and it should, with a high level of accuracy, be able to tell us what number that is.
Imagine you’ve been tasked to write a set of requirements for a new piece of software. The code in this application will receive an input of a hand written number and attempt to discern what number that is. Here are some sample images of what those handwritten numbers may look like:
Figure 1: Handwritten numbers (taken from the MNIST dataset)
For a basic rules-based set of instructions, how would you handle recognizing these images and translating them into digits? Let’s take 1 as an example. This can be pretty trivial if all 1’s were written as a straight line down. Perhaps we could write a requirement that reflects this. What happens with variations? How do we handle slants? Now let’s focus on a bit more complicated number: 9. How do we handle the tail? What if it’s backwards? All of these questions can either be handled by a single or series of algorithms but, for most of the laymen, we tend to write what’s called “exceptions.”
For example, “if the tail is slightly bent backwards by X degrees then we make an exception and that’s considered a 9.” There’s nothing wrong with this approach - in fact a very large amount of programming (especially in embedded systems) is based upon this branching technique (think branches in Assembly). The issue arises when we have to write not hundreds but thousands or millions of exceptions in order to get our algorithm, or “recipe,” just right. It’s like trying to curve fit a white noise waveform - which is, more or less, impossible.
In comes the neural network. In a human brain, neurons pass signals through synapses, adjusting their strength based on experience and learning. For example, when teaching a toddler number recognition, we reinforce those image-number associations time after time until their neural pathways develop the ability to recognize the images as numbers. The child has, essentially, gone through countless “trainings” and these neural pathways give it the ability to discern very quickly and accurately. Think of an exaggerated counterexample: we don’t give the child a thousand sets of rules or “if conditions” in hopes that after running through each permutation they’ll recognize the number from the handwriting - that would be preposterous. It would take them forever and it’s incredibly inefficient.
We perform a similar process with Artificial Neural Networks (ANNs). While there are no “neurons” or “synapses,” we do have “weights” and error correction mechanisms to build our neural network. The fundamental concept is relatively straightforward. Instead of programming explicit rules, we train the ANN with many examples. Each node in the network creates a simple function to represent portions of the data. Think of it like a piecewise function, which is a mathematical tool used to define different sections of a graph with different functions. This approach means we're not trying to create one big, complex equation. Instead, we break the problem into smaller, manageable pieces (or layers).
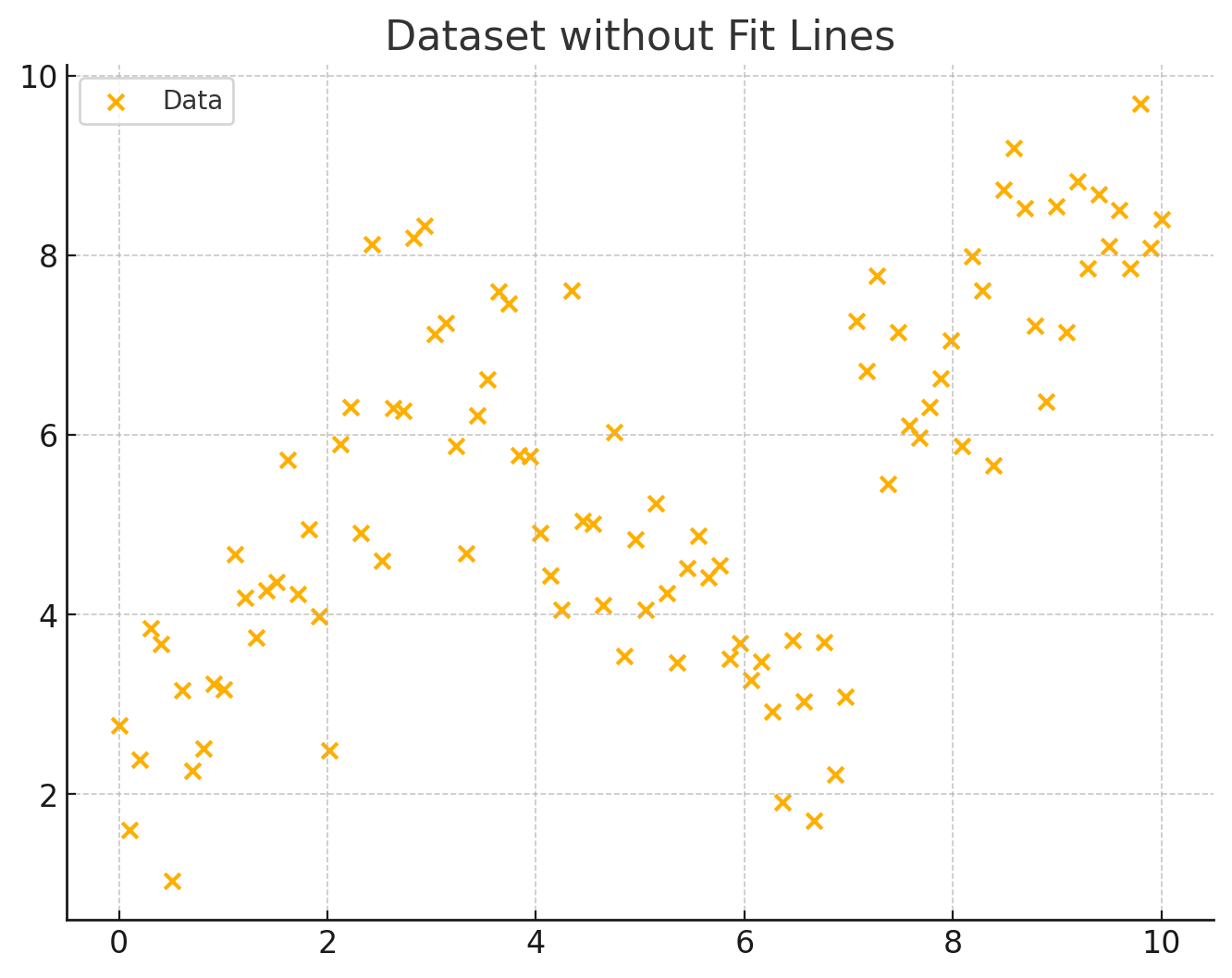
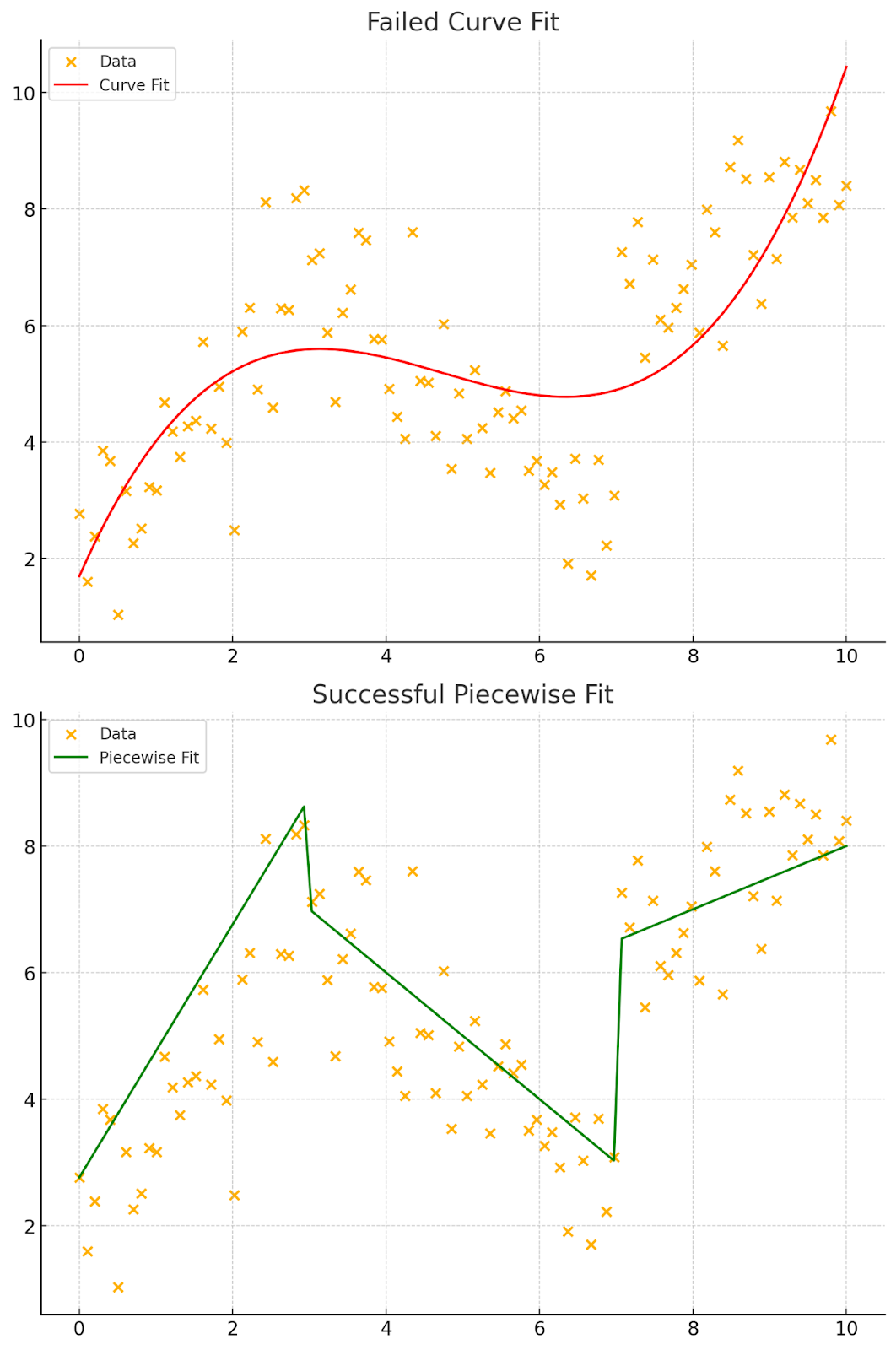
As we train our ANN we “reinforce” each weight with every new piece of data. The more data, the more reinforcement which translates into a stronger neural network. Just like with the child, we reinforce each step of the way until the final “model” meets the initial criteria. Just to illustrate, we can look at the following dataset and observe that attempting to curve fit with a single line (or equation) would be extremely challenging:
Figure 2: Sample Dataset
Figure 3: Curve Fitting versus a Piecewise Function
As you can see, using a piecewise function gives us a better approximation. In the handwriting recognition example, each step (or piece) gets us closer to identifying the number. The image of each handwritten number is made up of 28 by 28 pixels. For each pixel, we create a series of simple equations that help determine if it's a one, nine, or any other number. Instead of using one big equation to handle all 784 pixels at once, we break it down into many smaller steps (like pieces of a piecewise function). Each step fits a part of the data, and together, they help us accurately recognize the number.
Neural Networks in Practice
Now that we’ve discussed some of the fundamentals, it’s time to put theory into practice. Historically, creating a neural network involved complex mathematical derivations and manual implementation. Fortunately, modern libraries like PyTorch simplify this process significantly.
We start by defining the architecture of our neural network. Our model consists of two fully connected layers. The first layer transforms the input data (flattened 28x28 pixel images) into 128 neurons. The number 128 is a common choice because it strikes a balance between having enough complexity to learn patterns and being simple enough to train efficiently. Typically, the number of neurons can range from 64 to 512, depending on the specific needs of the model and the complexity of the task. The second layer maps these 128 neurons to the 10 possible digit classes, allowing our network to classify the digits. \import torch
import torch.nn as nnimport torch.optim as optimimport torchvisionimport torchvision.transforms as transforms# Define the network architectureclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(28 * 28, 128) # 28 x 28 pixels using 128 neuronsself.fc2 = nn.Linear(128, 10) # 128 neurons with 10 unique digitsdef forward(self, x):x = x.view(-1, 28 * 28) # Flatten the imagex = torch.relu(self.fc1(x))x = self.fc2(x)return xnet = Net()
The forward() method defines how the data flows through the network. First, we flatten the input image from a 28x28 grid into a single vector of size 784 (since 28*28=784). We then apply a ReLU (Rectified Linear Unit) activation function. ReLU helps the network learn better by replacing negative values with zero, while keeping positive values the same. This makes it easier for the network to focus on important patterns. If we kept the negative values, it would make learning slower and less efficient because those values can cancel out positive signals, making it harder for the network to identify key features. Finally, we pass the result through the second layer to get the class scores, which represent the network's guesses for each digit.
Next, we initialize our model, loss function, and optimizer. The loss function (CrossEntropyLoss) measures the difference between our predicted outputs and the actual data, guiding the network to improve its accuracy. The optimizer (SGD) then helps adjust the network's weights to reduce these differences. It does this by calculating gradients, which are like the directions and steps the network should take to improve its predictions. Think of gradients as arrows pointing the way to make the network's guesses more accurate. In short, this is what enables us to “curve fit” each piecewise piece to match the data as close as possible (which is an iterative process)
criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
We then load the MNIST dataset, a collection of handwritten digits, and set up a training loop. During each epoch (i.e. one complete pass through the entire training dataset) we feed the training data to the network, compute the loss, and update the weights. Again, this is just trying to curve fit and correct for each datapoint and we walk through the training process. Training for multiple epochs allows the network to learn and refine its understanding of handwritten digits, improving its accuracy over time. In each iteration, the network performs a forward pass to make predictions, calculates the loss to measure its errors, performs backpropagation to compute gradients, and updates the weights to reduce errors.
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True) # Training loop for epoch in range(5): for i, data in enumerate(trainloader, 0): inputs, labels = data optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # Save the trained model torch.save(net.state_dict(), 'mnist_model.pt')
Recall our discussion about training neural networks by adjusting weights based on examples. In our code, this is handled by the optimizer and the loss function, which work together to minimize errors. Each iteration through the training loop represents an opportunity for the network to improve its 'piecewise functions' and generalize better to new data. The use of ReLU activation functions introduces non-linearity, allowing the network to capture complex patterns in the data, much like how the human brain adapts and strengthens neural connections based on experience.
Conclusion
In this article, we explored the fundamentals of neural networks and how they differ from traditional rule-based programming. We then implemented a simple neural network using PyTorch to recognize handwritten digits, demonstrating how these theoretical concepts apply in practice.
While we’ve covered a lot in such a short article, there is so much more you can learn about neural networks. For those interested in understanding the math without diving into advanced Calculus and Differential Equations I highly recommend Make Your Own Neural Network by Tariq Rashid. Additionally, exploring other resources focusing on programming and theoretical foundations can be beneficial. Your journey to learning about neural networks will undoubtedly be piecewise and there is no one-size-fits-all approach.
Note: All the code for this project can be found in this repository.
About Author
Related Resources
Related Technical Documentation
Table of Contents
Design to Release, Without the Friction
- Keep reviews tied to the right version
- Reduce handoff confusion and rework
- Spot sourcing and release risk earlier
- Work solo, share when needed
Get Started
Thank you, you are now subscribed to updates.